Written by Fazal Hussain
A lot of readers that have found their way here will have extensive knowledge and experience in all things lean and continuous improvement. The essence of continuous improvement, as inferred by the name, is to continuously stive for better and identify new opportunities to improve. However, and as many of you will be aware, the tools we carry in our CI arsenal haven’t changed much in the last few decades. Familiarity with problem solving tools like the A3 approach, the 8D methodology or the DMAIC cycle are common knowledge for lean practitioners, however the holistic tools used to understand systems in their entirety are often rudimentary and limited to value stream mapping.
This article aims to raise awareness of a powerful tool, outlining its benefits and drawbacks and help integrate the tool into the continuous improvement process itself. The tool in question? Discrete Event Simulation!
The idea of simulation can be traced back as far as 1777, where the Monte Carlo method was used in the Buffon ”Needle Experiment”. Buffon randomly threw needles onto a surface in order to estimate the numerical value of Pi.
Although no computers or processing power was used in this example, it can be considered as simulation due to one main factor - Randomness. One of the main aims of simulation is to encompass the random nature of reality into the analysis of systems and the Monte Carlo Method does just that.
The Monte Carlo simulation is a randomly evolving set of events that can be used to solve problems that might be deterministic in principle. Let's take a simple version of the ”Needle Experiment” as an example but with the added assistance of a computer. A square container of dimensions A by A is placed on a weighing scale and the weight zeroed. The same is done with a circular container with a radius A. The two are placed next to each other on a table. A simulation then randomly picks a point on the table to drop a marble, with equal probability that the marble lands anywhere on the table. The number of marbles falling into each container are measured by the weighing scales.

Due to our understanding of mathematics we are aware that the number of marbles that will land in each container is a function of their surface area and the proportion between the two surface areas is Pi. When this experiment is completed in a simulation and using only randomness you can reach an estimation for Pi. When Buffon did a similar experiment in 1777 he claims to have reached a value accurate to within six significant figures and with the aid of a computer we can achieve an accuracy much higher than that. The main takeaway here should be that by using randomness we are able to estimate a constant that is mathematical and deterministic in nature, demonstrating the power of simulation.
It can go without saying that the use of computers has made simulation a much easier task, and as our computational capabilities continue to improve at drastic rates, so does the potential of simulation. Simulation is now often used in academic environments to aid in the solution of mathematical and physical problems, where it is often not possible or very difficult to use more direct methods.
Discrete Event Simulation (DES) did not come into existence until much later, with academic mentions of discrete event models in the 1960s. However, wide acceptance and ease of modelling was not available until the 1990s, aided by computational technology advancements. Although now widely available, DES is rarely used in real world environments, something I believe will soon change with the emergence of industry 4.0.
Traditional Continuous Improvement
The Importance of Data in Continuous Improvement
I wanted to take a little bit of time to review and discuss the current methodology widely used in continuous improvement, lean manufacturing, six sigma and all related topics. The majority of industries have now advanced to a point where the importance of process improvement is understood and there is a wealth of different techniques and methodologies that aim to do this. This article is not here to replace those methodologies or preach that one is better than another, they all have their advantages and the use of them often comes down to personal preference or experience.
The point that we aim to make is that all methodologies align to the same goal: process improvement, and that starts with understanding the current state of the process/system in question.
The majority of the current methodologies within process improvement put adequate emphasis on the power of data in decision making, however often the analysis of the data is rudimentary. Data is very powerful, even in its simplest form. However the potential of insights available with more thorough and advanced analysis is vast and currently largely untapped in the continuous improvement world.
Let's take a minute to look into other industries for inspiration. The use of data science to gain insight is very well established in sectors like sales predictions, HR, strategy and IT.

Within these functions, in house employees and consultants alike must use advanced data analysis techniques to keep an edge over competitors.
Philip Rowland, a Partner at a global management consultancy, OC&C Strategy, when talking about strategy decisions has said that “We are seeing more and more clients building their own analytics teams who are comfortable with multivariate regression, hierarchical clustering and decision trees, and dealing with data sets approaching big data territory.”
Now it is not being suggested that all improvement teams require this level of analytics, however to gain an edge over our competitors and to take the next steps in continuous improvement, the key must lie within more accurate information. It was Napoleon Bonaparte that first said “War is 90% information”, attributing most of his military success to having large amounts of precise information. While not directly comparable, when you’re battling for a competitive advantage in business, data and analytics can be equally important to your success.
It is for this reason I want to emphasise the importance of; collecting meaningful and accurate data, advanced analysis of such data and the use of simulation tools to support and represent this data. Steps that are often not fully explored in traditional continuous improvement projects.
Identifying Waste
Value Stream Mapping: A rudimentary yet powerful tool
At its core, identifying waste is arguably the most important part of any improvement journey. The ultimate goal of improvement is to eliminate waste and improve operational efficiency. The seven wastes often referred to are; defects, waiting, motion, inventory, over-production, over-processing and transportation.
A widely used tool to help capture these wastes is the Value Stream Map (VSM), where every step in a process in mapped with time and volume taken at each step. Each step is categorised as value add or non-value add, enabling a picture of the waste in the system to be built. There is vast amount of literature on how to successfully complete a VSM available if you aren’t already familiar.
The VSM is a powerful tool, its very simple to complete and gives a ‘big picture’ overview of existing product flows. The VSM is not a tool used to identify an optimal flow, it is a tool that helps uncover and shed light on the current system and helps hone efforts to reduce waste. There are many success stories which highlight prosperous improvement projects on the back of VSMs, however, they do have their limitations.
Firstly, VSM’s are typically produced with a combination of post-it notes and white boards in workshop style groups; leading to an easy, time effective gathering of collective knowledge. Unfortunately, due to its basic nature, VSMs often use singular, average values (for inventory quantities for example) and struggle once the system in question grows in complexity & granularity. Trying to map a complex manufacturing system or hospital onto a whiteboard can prove very difficult, especially when you are looking at a granular level. If you take the route of grouping or summarising processes to simplify your system, you can lose that all important granularity. The exact granularity that helps provide the precise information we need to make optimal, confident decisions.
For example, imagine a VSM is created in which three manufacturing cells are grouped as one process for the purpose of simplicity. The overall value add of that process is calculated to be 70%. Being content with this, the decision maker looks elsewhere in the map to reduce non-value add tasks/lead time. Unfortunately for them, they have missed an easy opportunity for process improvement because they lacked the granularity and breadth of data.
VSM does not mean “flow analysis” or the process of designing and creating optimum product flows. VSM is a simple tool to help operation managers and engineers (and others) understand how their flows currently operate. They help guide them through the process of analysis to improve those existing flows and design better ones in the future. The misunderstanding and downside of VSMs is when average values are used and taken as gospel by managers. Averages can be extremely dangerous when used to summarise a process, without a full understanding of the data set.
Finally, we need to take into account dynamics. The VSM is essentially a snapshot of your system, assessing the system at a certain point in time. In reality, your system could behave differently at different times, and when choosing where to focus improvement efforts this is an important consideration that cannot be overlooked.

Identifying Bottlenecks
An important step in improvement projects is the identification of bottlenecks, the processes that directly link to the limitation of throughput of the complete system. Now, anyone who has been in the industry for some time will know that the most common way bottlenecks are identified is by eye. An employee will notice the longest queue behind a certain process and identify it as the bottleneck.
In more complicated systems, where the bottleneck is not so obvious (for example in a service environment where the moving entity is information) process mapping is often completed. This is where the throughput of each process is measured in the form of an appropriate KPI, which is then compared with the process capacity.
Bottlenecks are often discussed in manufacturing environments, but they are incredibly relevant to most businesses and thus the above is purposely vague.

In a manufacturing environment the bottleneck could be a machine, so the appropriate KPI could be the OEE (overall equipment effectiveness) which compares the output to its theoretical maximum over a given time.
In a SAAS business, the bottleneck might be the number of account executives available to attend sales meetings, in which case the KPI would be number of account executives employed and the process capacity would be the employment budget in that department.
In any case, using the described methods only identifies severe and often obvious bottlenecks. If you wanted to proceed further and constantly remove the next bottleneck, you would quickly find you do not know enough about the dynamics of your system to know exactly where/when the bottlenecks are formed.
The Importance of Variation

An important and sometimes overlooked aspect when investigating a system is variation. Time and time again when systems are assessed, the average value of measurements are taken and used in further analysis. The variation is an incredibly important part of dynamic systems and absolutely cannot be overlooked if accuracy is valued.
The ‘new wave’ of six sigma enthusiasts has brought increased awareness of variation, specifically in the aim to reduce defects and achieve a 3 defects per million (six sigma) level. Six sigma rightly addresses process variation as a cause for errors and defects within products. To fully understand six sigma, you first need to understand that variation exists in everything (although sometimes too small to measure) and this variation effects your outputs and KPI’s.
Just to highlight the importance of variation in defects, a company operating at 3.5 standard deviations will typically spend 20-30% of their revenue on fixing these problems internally. This can be reduced to roughly 5% once you achieve 6 standard deviations (six sigma).
The variation is question can be caused by an array of different inputs including, people, shift patterns, difference in methods and environment, just to name a few.
I will admit the variation in defects, aided by the popularisation of six sigma, is widely investigated in many systems. Most businesses are aware of the effects of variation in their processes on defects and actively try to minimise these. Unfortunately, variation is overlooked in other areas whether that be throughput or lead time analysis.
What causes traffic jams?

To get an understanding of why variation is so important in all measurements, lets look at road traffic as an example.
Have you ever been sat in traffic on a motorway, expecting to see the cause for the queue once you get to the front? A few moments later the traffic jam clears without explanation. You may think the cause of the traffic jam is there are too many car on the roads, but when you drive around there is plenty of space for more cars to fit on the road. The culprit for this hour long wait on your journey home? Variation!
The variation in speed is the cause of traffic jams. Once the roads are operating near there capacity , any variation in speed of one vehicle will effect the vehicle behind it, which causes a knock-on effect to all the vehicles behind that and thus causes the traffic jam. If all the cars travelled at exactly the same speed, the roads could be populated to 100% capacity and there would still be no traffic jams. As an aside, it is the hope that as driverless cars become popular, the variation in speed (often caused by a human factor) will be reduced and there should be a reduction in queues.
This same principle is applicable to the systems we wish to investigate. Queues can be caused when processes are running near capacity and there is variation in speed of process/time taken. To understand these queues, which we know are a waste, we must when doing any analysis, consider the variation in all our measurements. If this is not done, our understanding of why we have queues in our system will be incomplete and any improvement projects taken on could be misguided.
Simulation can appear daunting to many, especially non-mathematicians, with the common misconception that years of training are required before you can successfully understand and build simulated models. This misconception comes in part from the misunderstanding between Continuous and Discrete Event simulations.
Most variables at the scales we tend to work on seem continuous to us (speed, acceleration, time), and if you were to consider all continuous variables when producing a simulation, the task at hand would indeed be immense. Fortunately for us, when the dynamics you wish to investigate are broad, a discrete event approach can be used.
In DES we approximate continuous processes into defined, non – continuous events. We model processes into a series of instantaneous occurrences (events) with the system approximated as fixed and unchanging in between these events. This allows us to investigate the system as a whole without worrying about how the event occurred, only that it did, the time it did and the effect of that event on the state of the system.
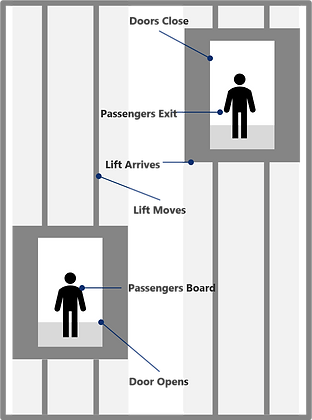
Lets take a simple example - an elevator. When considering an elevator there are many variables we could investigate, the current through the motor, the tension in the cables, the speed or acceleration of the elevator. Would this give us valuable information if our aim was to study the elevator’s efficiency at transporting people?
Instead, we could consider the elevator as a discrete system with a few discrete events. Let say for example we broke down the system into 6 discrete events:
•Door opens
•Passengers board
•Doors close and elevator moves
•Lift arrives at the correct floor
•Doors open and passengers exit
•Doors close
In between these events, the real world continues changing, however for the simplicity of our model, DES ignores these changes - they add no value to our macro view of the system. This model, instead, gives us the ability to investigate things like transit time, elevator utilization and passenger throughput – variables which add value when investigating the elevators ability to accommodate passengers.
We will discuss how to build a model in the next part however its worth mentioning a few ideas here that we need to keep in mind. As has been emphasized so far, any model must consider variation. One of the beauties of DES is the ability to consider this variation at every single step. When building a model the ”time taken” for a process to occur is not a constant but instead a variable distribution in the form of a probability density function. All the variation of the real world can thus be considered, vastly increasing the accuracy of the model without increasing the complexity much.
How to Build a DES model?
This article does not aim to be a one stop shop on how to build models, even DES takes time and dedication to master and we do not have the space here to fully explore all avenues of DES modelling. Instead, we will give an overview of what goes into building a DES model and implore interested readers to explore this fully else where.
First let's take a look at the different parts of DES simulation. There are 5 main components in a DES simulation: A start point, an activity, a queue, a resource and an end point.
The start point is where work items would enter our simulation, this could be anything from parts in a manufacturing line to customers in a supermarket.
Activity, is the part of the model where action is taken on the work item. This could be a process in a manufacturing line or the till at a supermarket.
Queues are used before activities to give work items that cannot move into the next step somewhere to wait.
Resources can be anything that is used by the activities. Common examples are employees that run either a machine in manufacturing lines or tills at the supermarket.
Finally the end point is where the work item will leave the model.
Each of these points have parameters that you can change, with the main parameter being the time taken for the event to happen, often added as a delay. So a queue with a minimum delay of 30 seconds could represent transport from one process to another. A delay on an activity is the amount of time that activity takes to complete. Other parameters include batch size and a variety of “code in” rules.
At each part, the time taken for something to be completed can and should be entered as a probability density function. On the majority of available software packages, there are options to either choose default function, enter a custom function or drop in a csv file with the distribution data and the software will help chose the best fitting function.
The ability to code custom rules and algorithms in the simulation software is a blessing, however it can sometimes become complicated. When routing your work items through your model, I would suggest it is easiest to code in an algorithm instead of battling your way through default functions, and it is not hard to pick up after a few practices. It also becomes incredibly useful when you start handling complex defect routes – i.e trying to include rework into the model.


Let us tie this off with a simple but step by step build of a DES model. We wish to study the factory plant of a car manufacturer, where our aim is to maximise productivity and minimise defects, and we decide to build a simulation to aid us in this.
In our simple version there is one line, the parts start at the beginning and are available when and where they are needed, a kitting trolley type situation. This is modelled with a singular start point.
We will then have 5 activities, chassis assembly, body assembly, painting, interior assembly and mating, with a queue associated with each activity.
A probability function is attached to the delay for each activity. Having been measured in the form of time stamps at the start and completion of each process, collated into a csv file and then dropped into a function finder tool within the software.
Finally we have an endpoint, labelled delivery.
Now we have completed our very simple model we can run the model, investigate the lead time, utilisation of the equipment and study the waste in the system. Much like the traffic jam example mentioned earlier, we have the ability to view the entire motorway from an aerial view, watching the waves of break lights form and ripple through the system.
To further improve this model we could delve deeper into each process and break them down into individual tasks. We can add rules as to which work items take which routes given other inputs (either random, distributed, or down to some given attribute).

Useful Tools
“All models are wrong, but some are useful” George Box, Statistician
Before we mention the power of simulation and what makes it so useful, I wanted to take a minute to mention the importance of understanding the model.
Modelling is a way we can solve real-world problems. In many cases, we can’t afford to experiment with real objects to find the right solutions: building, destroying, and making changes may be too expensive, dangerous, or just impossible. If that’s the case, we can build a model that uses a modelling language to represent the real system.
The modelling of a process/system assumes abstraction: we include the details we believe are important and leave aside those we think aren’t important. The model is always less complex than the original system. For that reason it is always ‘wrong’, it will not account for every minute detail, but instead provide a realistic enough insight as to how the system behaves.
The collection and modelling of data can be conducted in a multitude of different ways. The 3 main ways to input uncertain data are; trace-driven, empirical or theoretical.
Trace driven – observe the process directly and record the inter-arrival times. E.g. using a clicker. This simple method uses real data only, is simple to understand and can be used for validation. It is however highly time consuming, based on historic data only and difficult to generalise. As it is based on historic data only, trace driven data input fails to identify the extreme variations that may happen rarely (not observed during the sample time).

Empirical – Observations are converted to piecewise linear approximations. This allows intermediate data to be generated, requiring less data recording. It does however also miss potential extreme values that were not recorded during the sampling stage and still requires a relatively large data volume.
Theoretical – Fitting data points to a hypothetical distribution. This method is the most computationally efficient, concise and accurate. It does however require modelling knowledge of stochastic processes, in other words, requires the users-skillset to correctly match and select a hypothetical distribution.
One of the difficulties with building a simulation is that all models are limited by the accuracy of the data entered. You, however, are limited by time and need to find the ‘right level’ of accuracy.
In certain instances you will have thousands of easy to read inter-arrival times for a process, in other instances you will have to manually record times yourself. There are however certain tools that can be used within DES to help speed things up and create more accurate models.
Expert system tools that conduct automatic ‘goodness of fit tests’ are available. E.g Statfit or Expertfit. These tools allow you to enter your data and be presented with an accurate probability function as the input to your model, conducting the theoretical method for data input automatically.
Motion Trackers and 3D rendering
Even with these tools, data still needs to be recorded and input. One tool I use to speed this process up is to use motion trackers. Small UWB trackers can be attached to work items (where possible) as they go through the system giving you precise data on the full system in one go. It’s possible to do this with 50 or so trackers at a time, allowing you in a single day to gather enough data about your full system to build probability functions for each part.
Something that has evolved rapidly in the past years is the ability to 3D render simulations to mimic real world cases. The described simulation is very much a flowchart style simulation but can be made to look incredibly realistic. The processing power and graphical capabilities of computers continues to grow and with it so does the visual realism. Models can be rendered to look ‘life-like’ and very closely match the real life system. This feature is both extremely powerful but also dangerous. It is a great convincer, to help demonstrate the closeness and accuracy of the model to reality. However, by looking so realistic, the capabilities of the model can be exaggerated when compared with an equally accurate 2D model. For that reason, I personally suggest spending 90% of your available time modelling the system then only 10% on 3D rendering – the accuracy of the model ultimately dictates its value.

DES is an excellent tool to fill in the gaps of current methodology
Now we have understood the limitations of traditional continuous improvement methodologies and how to build a DES model, the question we should answer is, Can DES help? Why should we use it? How much does it help?
The short answer is: Yes, DES is an excellent tool to overcome the limitations in other tools such as VSM.
We’ll start our argument with the all-important variance. We now understand how our models can consider the random variations that we find in real life. But we have only touched upon this subject lightly.
The ability to add variation to your analysis is embedded into each part of most DES software. If you have resources in your model you can enter a schedule by which these resources are available, and into that you can enter variability of resource availability, essentially accounting for sick days of your staff or fluctuations in energy supply. The power the simulation gives you to make predictions in the face of randomness is incredible and in my opinion one of the main advantages.
The simulation also provides a plethora of metrics and KPI’s. Utilization of any single activity or resource can be investigated. Value add time, process time, lead time, queuing time and more is available for each process individually, any group of processes and the system. Not just averages, you can examine maxima and minima, when they occur and the variability between them.
The ability to see the queues in the simulation and quantify the rate of queue at each process dynamically allows you to easily identify bottlenecks, examine what times they occur and work out the cause for it.
Resource utilization is easily accessible even in systems with complex schedules. The majority of software has tools allowing resources scheduling to be done easily and variation input into the amount of resource needed for an activity to be completed. The simulation can now be a tool in the aid of resource allocation, giving you predictive power over your workforce and other resources.
I want to also emphasize the power of a dynamic analysis tool. As much as we would like them to, real world systems do not run at a constant instead they are constantly changing and the ability to predict and analyse these systems traits is incredibly important
Now, all of these advantage are great in their own respect, but the real excitement comes from the combination of them all. As the analysis is done in one software the link between things can be identified easily. If a certain bottleneck is being caused by a lack of available resources, the model will show that. If the throughput at certain times is being limited by a bottleneck, the model with tell us. If money is being wasted through an under-utilized activity, the model will expose that. It really gives us the power to look at our site as a dynamic and intertwined system and understand all aspects of it.
Finally, I want to talk a bit more broadly about use and there are two point to be made here.
The first is ease. Once you get the hang of simulation you will likely find it much easier than the previous postit/whiteboard methods. You are able to save your work, zoom in and out of your system, add side projects, and increase and decrease granularity as you go along. Once you’ve built your first model, you can keep it, amend it as needed and the majority of the work for your next improvement project is already done. As the IT literacy of the population continues to increase, I believe this will become the easier and more user-friendly option.
The second point I wanted to make was visualization. The added value of being able to see a computer model that represents an exact replica of the system in question gives a lot confidence to all stakeholders involved. Often analysis is questioned when not understood and the beauty of simulation is that there is nothing to be not understood, you can run the simulation at 1x speed and watch the analysis unfold in front of your eyes. When trying to convince stakeholders to part with their money for a new improvement project, the confidence a simulation can provide is invaluable.
Testing with DES
Using simulation to test suggested improvements
One of the most difficult things with improvement work is predicting the outcome of proposed improvements. Most of the readers here will have identified an opportunity for improvement, proposed a solution and gone through various testing phases in order to assess the solution. This can vary from scenario analysis and mathematical predictions to sandbox and pilot schemes.
The problem faced here is the uncertainty that comes with implementing solutions in a live production environment. There is little room for error and the cost of a system being offline can grow very quickly. This is where simulation can provide a unique advantage.
Once a simulation has been produced for a current state and opportunities for improvement are identified, the next step is to propose solutions. The beauty of simulation is that many different proposed future states can be simulated and thoroughly tested to see the effect on the part in question and the system as a whole. All of this can be done without disruption and with relative ease.
Using this method, you don’t just enable solutions to be tested without interfering with your live system, but you also increase the accuracy of your predictions.
A recent case study directly compared the accuracy of DES compared to traditional methods for identifying opportunity. The simulation aimed to predict the increase in capacity after rearranging a factory floor and redistributing operator resources.
Traditional data analysis methods predicted a 46% increase to capacity while the simulated model found a 30% increase. Once the final improvement had been made the increase was found to be 31.3%. The greater accuracy associated with DES helps companies make informed, confident decisions that can enable large cost savings to be made.


Every company starts their continuous improvement journey in a different way and proceeds to use the tools that the company are typically familiar with. These tools vary from 8D problem solving to value stream mapping. Ultimately continuous improvement is about the accumulation of both incremental and step change (breakthrough/blitz) low cost improvements made on a frequent basis; improvements to reduce waste or muda.
This article does not aim to change the fundamental CI mindset, instead it aims to bring awareness to a highly powerful tool that should be added to your arsenal. Simulation is a great tool to capture the mura or variation within a process/system, variation that often leads to muda.
Any robust improvement process starts with a thorough assessment of the current state. Normally this would include collecting and analysing data to better understand the process. To integrate simulation into the process small changes need to be made.
Firstly, in the data collection phase, it is important to ensure we have multiple measurements of each variable we take so we can build up probability functions to be input into the simulation. This is also just good practice. Even if you weren’t to use simulation, if you could investigate the standard deviation in all your measurements you would be able to identify areas of high variability, which we know we want to minimize.
Then we come onto the mapping phase. The mapping phase can be done in a similar method to currently, in a workshop style with the collective knowledge of multiple stakeholders, with the addition of your chosen simulation analyst building the virtual map alongside the traditional whiteboard and post its. I find its often easy to put together the flowchart style map in DES software and can be done alongside the physical one in similar times, so this meeting should flow as normal.
An extra step is now needed, where the simulation analyst takes the data collected and increases the accuracy of the model by including the data for variability. This can sometimes be time consuming for complex systems however only requires one team member and can be done in the background.
At this point you should have KPI’s and metrics from both physical calculations and simulated results, along with a physical and virtual map of your system.

Using this assessment you can move onto the problem-solving part of improvement. There is a vast amount of literature on problem solving techniques and I’m sure the reader has one they prefer and thus I won’t explore them here. Instead we will jump to testing. Having identified a few different solutions it’s time to bring out the simulation again. Each solution should be simulated as a separate future state, with predicted variation included, even if that is purely random fluctuation around a mean (Normal Distribution). Each future state simulation will provide KPI’s and you can select the future state you aim to reach using these KPI’s, ensuring you do look at the system as whole and not just the changed parts.
Once you have implemented your proposed changes, and reached your future state, it is important to keep your simulation up to date. New measurements should be taken of the changed parts and the exact variability entered into the simulation.
Now, once our proposed future state becomes the current state, we already have the analysis stage of the next improvement process complete. We can jump straight back into the simulation and investigate the next improvement idea.
Once the initial simulation is built, the upkeep and modification of the model is relatively simple. You can increase the complexity if you think it would be of use. However, the continuous improvement process can progress as normal from herein, with the addition of a more accurate and all-round beneficial tool to your deck.
The success of Panasonic's integration of data collection and simulation
I’d like to finish by giving a real-world example of the potential of the use of technology such as simulation and more.
Panasonic has recently tested a continuous improvement method they are calling “gemba”, built on the Kaizen method at Toyota. The aim of gemba is to add data collected on the ground and shop floor to the kaizen methodology, with the aid of IoT, AI and simulation.
Tested at its Saga plant in the northwestern part of the Kyushu Island, the gemba system was introduced by the consumer electronics group to make the Saga plant into a “smart” factory and an Industry 4.0 showcase.
The initiative was closely tracked by specialists at Actemium, the VINCI Energies brand dedicated to industrial performance. Steve Bullock, Actemium Innovation Manager in Spain, says that “Gemba is an advantageous system that encourages managers and engineers to closely scrutinise what is happening on the ground, in the industrial processes, in order to identify the actual problems occurring in their manufacturing plants.”
At the Saga plant, Panasonic installed about 40 beacons in the ceiling to geo-locate operators and monitor their movements with the machines. This along with data collection on their machines allowed to to track everything that happened on the shop floor. The data captured was analysed and entered into a simulation which prompted process change.
”We typically increase productivity by 10% per year”
Tomokazu Ichiriki
Director of Manufacturing, Panasonic
In this experiment, Panasonic connected actual manufacturing premises, machines, employees, IoT, Ai and simulation. The combination ultimately provides a detailed understanding of the reality of an industrial process and makes it possible to optimise the configuration of machines and adjust operations.
This worked exceptionally well in this case, as automation was not easily possible. Over 70% of the plant’s production runs comprise between 1 and 100 units. To achieve this and adapt to fluctuations in demand, the plant must be constantly reconfigured. It must be flexible but also meet stringent efficiency, productivity and quality standards.
“We do not produce large volumes that would warrant large-scale automation,” says Tomokazu Ichiriki, Director of the Manufacturing Technologies Department at Panasonic. “We have to find the right trade-off between manual work and automation and identify the manual tasks that would really warrant the introduction of robots.” By analysing the data captured and with the aid of simulation, “We typically increase productivity by 10% per year,” he adds.
The main takeaway from this is the how the use of data and technology together gave them the ability to continuously make improvements to their productivity.
This example is obviously on the further end of the spectrum, with large investment into technology, but the same can be achieved with robust data collection and the use of tools such as simulation.

